우선 인코딩이란?
인코딩 : 문자를 어떻게 출력할지에 대한 약속.
가장 처음 만들어진 인코딩이 ASCll 코드 ( American Standard Code for Information Interchange )
: 지극히 영어권 언어 중심적인 인코딩 방법
A, B라는 문자를 100 0001, 100 0010 처럼 컴퓨터가 이해할 수 있는 숫자로 표현.

128개의 문자 조합을 제공하는 7bit 부호
* 1바이트를 구성하는 8비트 중에서 7비트만 쓰도록 제정된 이유는, 나머지 1비트를 통신 에러 검출을 위한 용도로 비워두었기 때문.
일본, 중국, 한글 인코딩은 글자 조합이 2바이트 이상을 써야 가능했기 때문에 아스키 코드를 건드릴 수 밖에 없었고, 초창기에는 글자 깨짐 문제가 종종 발생하였다. 코드페이지(CP949 등)를 맞춰주지 못하면 역시 글자 깨짐이 발생했고, 해외 게임을 할 때 특히 그러했다.
그래서 탄생한게 유니코드이다. 그러나 유니코드가 제정되면서 글자 깨짐은 끝날 줄 알았지만 멀티 바이트의 엔디안 문제로 글자는 또 깨졌고, ASCII가 호환되는 UTF-8이 널리 사용되면서 글자 깨짐은 막을 내리게 된다.
자~
뭐라고 뭐라고 써있는데 천천히 모르는 용어에 대해 알아보면서 이해해보자.
유니코드(Unicode) : 각 나라별 언어를 모두 표현하기 위해 나온 코드 체계가 유니코드
: unicode.org 가보면 code chart라는 항목이 보이는데 모든 글자를 맵핑 해놓은 차트를 볼 수 있다. 한글은 AC00 부터 맵핑되어 있으니깐 AC00을 검색해보면 아래 처럼 매핑된것을 확인 할 수 있다.
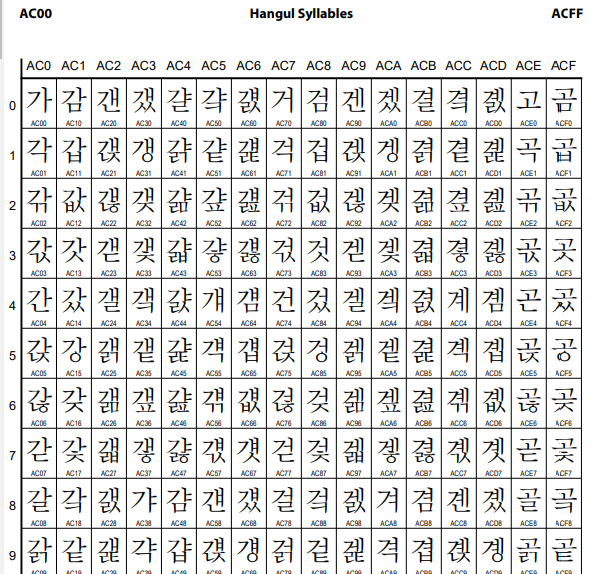
아스키 코드가 1바이트에 문자를 표현했던 것과 달리 유니코드는 16비트( 2Byte) ( 16진수 4개 )로 전세계의 문자를 표현.
초기에 유니코드는 0x0000 부터 0xFFFF 까지 2^16에 모든 문자를 집어 넣었었다.
그래서 사용중인 운영체제, 프로그램, 언어에 관계 없이 문자마다 고유한 코드 값을 제공하는 새로운 개념의 코드
16비트를 표현하므로 최대 65,536자 표현 가능 ( 0 ~ 65,535 : 2 Byte 최대 표현 가능 숫자 )
숫자와 글자, 즉 키 값이 1:1로 매핑된 형태의 코드( 완성형 코드 페이지 )
여기서 주의해야 할 것이 유니코드는 '인코딩'이 아니라는 것이다. 유니코드는 전세계 거의 모든 문자를
2bytes 숫자로 1:1 매핑 시키는 '방식'을 말하고, 유니코드를 표현하는 여러가지 '인코딩' 방식들이 존재하는 것이다.
UTF-8, UTF-16 등이 그 인코딩 중 하나인 것들이다.
여기서 '가'를 찾아보면 유니코드 값이 'AC00' 인 것을 알 수 있다. 16진수 AC00은 10진수로 44,032 인데 8bit로 나누기에 너무 크다. 이 값을 8bit 단위로 쪼개어 저장하는 방법이 UTF-8이다.
* 참고 :
90년대 부터 MS사가 급부상 하면서 문자를 표현함에 지들만의 것을 쓴다. Multi Byte Character stream? string? 이렇게 표현한다.(MBCS)
EUC - KR 는 유닉스 계열의 완성형 코드페이지로 역시 가변길이 방식의 형태이다. 영어,특수문자 는 1 Byte 로 한글은 2 Byte 로 표현하고, CP949 보다 작은 수의 한글을 표현 할 수 있다.
CP949 ( code Page 949) 또한 유니코드 처럼 확장 완성형 코드 페이지이고, 완셩형 코드표에 없는 한글 글자를 조합형으로 처리하는 로직을 가지고 있다. 윈도우 계열의 코드 페이지 이며 통상 영어,특수문자 는 1 Byte 로 한글은 2 Byte로 표현한다. MS 에서 EUC-KR 을 개선, 확장해서 만든것이 CP949 이다. MS 가 만들었다고 해서 MS949 라고도 부른다.
UTF-8 은 전 세계 모든 문자 코드 페이지를 포함하는 가변 길이 문자 인코딩 방식이다.
영어나 특수 문자와 같은 통상 문자는 1Byte 즉, ASCII 코드에 있는 것은 그대로 1Byte로 표현. 한글은 3Byte로 표현한다.
하지만 2^16개의 자리로도 부족해지자 0x0000부터 0xFFFF까지 문자를 배정해놓은 세트를 총 17개로 늘리게 된다.
이 세트들을 유니코드에서는 "plane" 이라고 부르고, 앞에서부터 0번 ~ 16번 까지 번호를 붙여놓았다.
( 현재 사용되고 있는 plane 은 0~2번과 14~16번의 planes. )
이 plane 중에서 현대에서 쓰이는 문자들을 모두 0번 plane에 몰아넣었는데 이 plane을 기본 다국어 plane(BMP, Basic multilingual plane)라고 한다.
유니코드를 표시하는 방법 : U+
유니코드에서는 모든 plane 이 0x0000부터 0xFFFF의 값을 가지고 있기 때문에 문자끼리 겹치는 현상이 발생했다.
예를 들면, 0xB000은 0번 plane 에서는 한글 “뀀”이지만, 1번 평면에서는

라는 글자가 된다.
이런 문제를 해결하기 위해서 유니코드에서는 U+ 라는 기호에 plane의 숫자를 붙이는 방식을 사용했다.
( 0번 plane의 경우는 숫자를 붙이는 것을 생략.)
ex) 한글 “뀀”은 0번 plane 에 있으니 아무것도 붙이지 않고 U+B000라고 표시하고,

는 1번 plane에 있으니 U+1을 붙여서 U+1B000으로 표시한다.
유니코드 인코딩 종류
유니코드로는 세상에 존재하는 거의 모든 문자를 표현할 수 있지만, 그만큼 바이트를 많이 사용하기 때문에 용량이 크다는 문제가 있다.
또, 첫 번째로 평면을 표시하는 숫자를 앞에 붙여야 하기 때문에 문자를 표시하는 바이트 외에 자리가 더 필요한 상황이 되었다.
이런 문제를 해결하기 위해서 유니코드는 많은 인코딩 방식을 가지고 있다.
유니코드의 인코딩 방식으로는 UCS-2, UCS-4, 그리고 UTF-8, UTF-16, UTF-32 등이 있다.
[ UCS-2 ]
UCS-2 방식은 유니코드의 모든 평면의 문자를 모두 인코딩 하지 않고, 0번 기본 다국어 plane (BMP)만을 인코딩하는 방식.
plane[0]의 0x0000~0xFFFF까지의 문자를 그대로 고정 2바이트 형식으로 표현한다.
ex) 유니코드에서의 한글 “가”에 해당하는 16진수 숫자 0xAC00을 UCS-2로 인코딩 하면 [0xAC 0x00]이 된다.
UCS-2의 장점
유니코드에서 평면을 나타내는 숫자를 떼어버렸기 때문에, 1글자의 크기가 딱 2바이트로 깔끔하게 떨어진다.
UCS-2의 단점
1. 2바이트를 사용해서 문자를 표현하기 때문에 엔디안 문제가 발생한다.
ex) 0xAC00은 빅엔디안을 사용하는 시스템에서는 한글 “가”가 되지만, 리틀 엔디안을 사용하는 시스템에서는 ¬ 라는 제어문자가 되버린다.
이를 해결하기 위해서 UTF-8과 UTF-16은 2바이트인 BOM(Byte Order Mark) 을 유니코드 파일이 시작되는 첫 부분에 명시해서 문자열이 어떤 엔디안 방식을 사용하는지 명시하도록 하였다.
>> BOM 자세히 <<
BOM이란
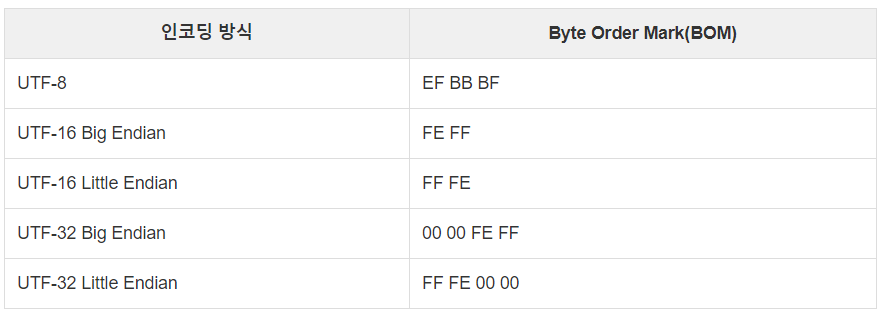
BOM이란 문서 맨 앞에 눈에 보이지 않는 특정 바이트(byte)를 넣은 다음 이것을 해석해서 정확히 어떤 인코딩 방식이 사용되었는지 알아내는 방법을 나타냅니다. 자세하게 유니코드가 little-endian 인지 big-endian 인지 아니면 UTF-8 인지 쉽게 알 수 있도록, 유니코드 파일이 시작되는 첫부분에 보이지 않게, 2~3바이트의 문자열을 추가하는데 이것을 BOM이라고 합니다. BOM은 텍스트 에디터 화면에서는 보이지 않고, 헥사 에디터(Hex Editor)*로 열었을 때만 보입니다.
BOM의 종류
| UTF-8 | EF BB BF |
| UTF-16 Big Endian | FE FF |
| UTF-16 Little Endian | FF FE |
| UTF-32 Big Endian | 00 00 FE FF |
| UTF-32 Little Endian | FF FE 00 00 |
UTF-16 이상 인코딩일 때, 문서의 맨 처음 BOM을 파악하여 Big Endian인지 Little Endian인지 구분하지만 UTF-8의 경우는 BOM이 하나로 고정입니다. ( 리틀 , 빅 엔디안 문제가 없다. 기본 1바이트씩 읽으니깐 ) 따라서 실제로는 BOM이 불필요하다.
그래서 이 BOM은 바이트 순서와(Byte Order) 상관없기 때문에 UTF-8 Signature라고 불리기도 합니다. 즉, 해당 문서가 UTF-8로 인코딩되었다는 사실을 알리는 사인(signature)입니다.
UTF-8 BOM 문제점
UTF-8은 인코딩 형식이 고정되어 있기 때문에 BOM이 없어도 인코딩 방식을 자동으로 알아낼 수 있습니다.
하지만 일부 윈도우즈 프로그램(메모장 같은)은 UTF-8 파일을 생성할 때 자동으로 BOM을 집어넣습니다. 윈도우즈 환경에서는 눈에 띄지 않는 경우가 많지만 리눅스(LINUX)나 유닉스(UNIX) 환경에서는 많은 문제를 일으키는 원인이 되지요.
그래서 같은 파일이라도 BOM 이 있는 UTF-8 과 BOM이 없는 UTF-8 이 다르게 됩니다.
BOM 문제를 해결하는 방법
가장 좋은 방법은 BOM을 처음부터 넣지 않는 것입니다. 윈도우즈의 메모장 대신 BOM 설정이 가능한 전문적인 텍스트 에디터를 사용하는 것이 좋겠지요.
에디트플러스 라는 텍스트 편집기에 ‘Always remove signature’로 지정하면 편집하는 모든 파일의 BOM이 제거됩니다. 다른 텍스트 에디터에도 비슷한 설정이 있는 경우가 많습니다. 예를 들어서 프리웨어 텍스트 에디터인 Notepad++는 옵션 설정 창의 ‘New Document’ 탭에서 인코딩 방식을 ‘UTF-8 without BOM’으로 설정하면 BOM이 없는 UTF-8 문서를 만들 수 있습니다.
ex) 한글 “가”는 BOM이 0xFE FF라면(빅엔디안) 0x0048이 되고 BOM이 0xFFFE라면(리틀엔디안) 0x4800으로 저장된다.
2. 0번 평면의 문자들만 인코딩 했기 때문에 모든 유니코드 문자를 표현할 수 없다.
[ UTF-32 ]
기본 다국어 plane(BMP)만을 이용한 UCS-2와는 달리 UTF-32는 유니코드의 모든 문자를 표현하기 때문에
한 글자당 32비트(4 Byte)를 사용하는 인코딩.
표현 방식
UTF-32에서 앞에 2바이트는 [0x00 0x00]와 [0x00 0x10]는 몇 번째 평면인가를 표시.
그리고 뒤에 2바이트는 UCS-2와 같이 해당 평면의 어느 문자인지를 나타냅니다.
ex)

UTF-32의 장점
유니코드를 그대로 4바이트 자리에 가져다 놓았기 때문에 유니코드와 비교하기 쉽고, 한 글자에 고정 4바이트를 할당하기 때문에 문자열 처리가 간결해짐.
UTF-32의 단점
1. 한 글자에 고정적으로 4바이트를 할당하기 때문에 다른 인코딩 방식에 비해서 상당히 많은 용량을 차지하고 있다.
ex) 같은 문자라도 ASCII 코드와 비교해서 용량이 4배나 차이가 나게 된다.
2. HTML5에서 사용 금지
→ HTML5.1 사양 4.2.5.5 챕터에는 아래와 같이 명시되어있다.

이런 문제들 때문에 UTF-32은 거의 사용되지 않고 있다.
[ UTF-16 ]
UTF-16은 너무 많은 용량을 사용하는 UTF-32 인코딩의 문제를 해결하기 위해 나온 가변 길이 인코딩 기법.
UTF-16은 기본 다국어 plane ( plane[0] ) 에 속하는 문자들을 표현할 때는 UCS-2와 같지만, 2바이트를 넘어서는 문자는 4바이트를 표현하도록 하여 문제를 해결했다.
그래서 기존의 UCS-2 16비트 인코딩과 호환이 되면서도 16비트를 넘어서는 문자를 가변 길이 인코딩으로 표현이 가능하게 되었다.
문자 표현
2바이트 : 기본 다국어 평면(BMP)
- 장점 : UCS-2 와 같이 plane[0]의 0x0000~0xFFFF까지의 문자를 그대로 고정 2바이트 형식으로 표현한다.
- 단점 : 글자 하나를 무조건 2바이트(16 bit로) 사용하기 때문에 little endian 인지 big endian 인지 문제가 생긴다.
-> UCS-2 와 동일한 문제 그래서 UTF16 - LE 인지 UTF-16 BE 인지 구분해준다.
4바이트 : 2바이트를 넘어선 모든 유니코드 문자
ex1) 영문 소문자 z는 기본 다국어 평면의 0x007A 자리에 배정되어 있으므로, UTF-16에서는 [0x00 0x7A]로 표시 된다.
- 단점 : 7A 면 표현 가능한것을 0x00 7A 로 표현하게 된다. (UTF-8 은 0x7A 로 표현. 대신 한글은 3Byte )
ex2) 한글 “가”는 기본 다국어 평면의 0xAC00 자리에 배정되어 있기 때문에 UTF-16에서는 [0xAC 0x00]으로 표시 가능.
기본 다국어 평면를 제외한 문자들은 위의 예제와는 다르게 4바이트로 표시한다.
그리고 위처럼 간단한 규칙이 아닌 복잡한 규칙을 통해서 문자를 표현하게 된다.
복잡한 규칙은 상당히 복잡해 보여서 우선은 Skip.. 그 정도까지는 머리속에 안담아도 될 것 같다.
UTF-16의 단점
- 최소 2바이트를 사용해 문자를 표현하기 때문에 엔디안 문제가 발생.
→ 리틀 엔디안 인지, 빅 엔디안 인지에 따라 값이 바뀔 수 있다.
: 그래서 메모장이나 텍스트 에디터에 저장할때 UTF-16 다음에 오는 LE ,BE는 이 엔디안 방식을 나타내는 것이다.
- 아스키 코드와 호환되지 않는다.
→ 최소 2바이트를 사용하기 때문에 1바이트를 사용하는 아스키코드랑 호환되지 않는다.
대표적으로 UTF-16을 사용하는 곳
Java의 String, 윈도우 운영체제의 메모리 저장
UTF-8 (가변길이 인코딩) : 유니코드를 사용하는 인코딩 방식 중 하나
- 가장 많이 쓰이는 방식
영문/숫자/기호는 1바이트로, 한글/한자는 3바이트로 표현
전세계 모든 글자들을 한꺼번에 표현할 수 있다.
UTF-8 유니코드는 ASCII 코드와 영문 영역에서는 100% 호환
만약, UTF-8 유니코드 문서에 한글 등이 전혀 없고 영문과 숫자로 이루어져 있다면 그 카드는 아스키코드와 동일.
UTF-8은 가장 많이 사용되는 가변 길이 인코딩.
문자에 따라서 1바이트 ~ 4바이트로 인코딩 될 수 있으며, UTF-16과 다르게 아스키 코드와 하위 호환성을 가진다.
보통 유니코드가 널리 쓰이기 전에 형성된 문서나 프로그램이 아스키 코드를 기반으로 작성되었기 때문에 UTF-8은 이 부분에서 많은 장점을 가지게 되어서 널리 쓰이게 되었다.
UTF-8 은 인코딩 하는 기준이 있는데 외울 수 없으니, 그냥 있다라고만 알아 두자.
UTF-16 에서는 일단 적어도 한글은 그냥 유니코드 표 상에 있는 16진수 값을 그대로 사용하는것 같다. ( 같은 2Byte )
* 참고 :유니코드 에 있는 U+OOOO 을 UTF-8 로 인코딩 하는 방식
https://blog.naver.com/bbmobile/221360230141
[ URL 인코딩 ]
- 기본적으로 UTF-8 사용.
인터넷 URL에 이렇게 한글로 검색하면 web에서는 UTF-8로 인코딩해서 한글 한글자당 3 BYte 로 처리하고 있다.
바이트 앞에 %를 붙혀준다.
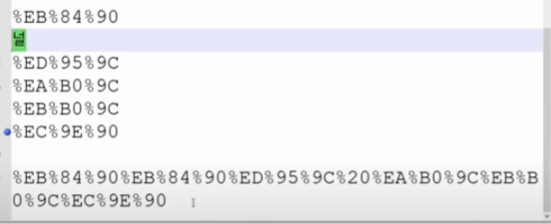
[ Ref ]
https://namu.wiki/w/%EC%95%84%EC%8A%A4%ED%82%A4%20%EC%BD%94%EB%93%9C
아스키 코드, 유니코드 그리고 UTF-8, UTF-16
인코딩 부호화나 인코딩은 정보의 형태나 형식을 변환하는 처리나 처리방식 문자 인코딩은 문자들의 집합을 부호화 하는 방식 → 어떤 정보를 미리 약속한 규칙으로 가공하는 것입니다. 문자
dingue.tistory.com
https://www.youtube.com/watch?v=6hvJr0-adtg
'Work > work log' 카테고리의 다른 글
| 컴파일 과정, extern, static ( feat. Mutiple definition of '...' 에러 ) (0) | 2022.07.02 |
|---|---|
| [C++] enum elements 들을 대응되는 string(문자열) 로 바꾸려고 하면서.. (0) | 2022.06.20 |
| [Work] Log 출력 매크로 참고 (0) | 2022.06.20 |