atomic 도 좋지만은 일반적으로 lock을 거는게 조금 더 일반적이다.
아래의 코드의 결과를 예상해보자.
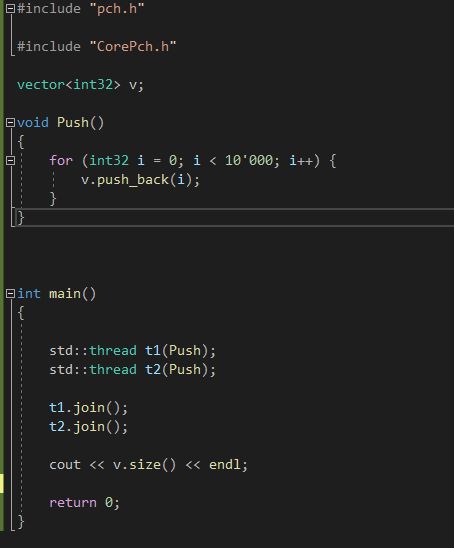
크러쉬가 난다. ( 꼭 이유를 생각해보자. )
vector 같은 경우 , 한 쓰레드가 push_back 할때 capacity 늘리고 이전 vector 공간 삭제할텐데
이때 다른 쓰레드가 늘릴려고 capacity 증가 시키고 동일하게 이전 vector 공간 삭제하려고 한다면 double free 문제가 생긴다. ( 이걸 생각해 내는게 어렵다... )
그렇다면 reserve(20,000) 으로 이미 공간을 많이 확보해 놓으면 어떨까 할 수도 있지만
vector가 데이터를 넣을때 마지막 인덱스 값(size)을 알고 넣기 때문에, 두쓰레드가 벡터에 거의 동시에 넣게 된다면 조금 늦게 값을 쓰려고하는 쓰레드는 벡터의 size를 안 시점에서는 size가 3이라 3번째에 데이터를 넣으려고했는데 더 빠른 쓰레드가 하필 바로 직전에 해당 3번째 벡터에다가 값을 넣었다면 덮어 씌여질 수 있다.
그리고 실제 reserve(20000) 하고 코드를 실행해보면 결국 데이터가 20,000개가 나오지 않고 일부 데이터가 분실이 일어난것을 알 수 있다.
그럼
atomic<vector<int32>> a;
처럼 atomic을 쓰면 안될까?
atomic 은 일반적인 데이터 primitive 한 데이터해서 동작하지 vector 같은 데이터에서는 사용할 수 없다.
atomic은 atomic 변수에다가 직접 store 나 load 같은 연산을 하는거지 vector 에 있는 기능을 활용 할 수 는 없다.
물론 list 나 다른 stl 들은 다른 이유도 있겠지만 모두 싱글 스레드 방식에서만 동작하는 방식이기 때문에 항상 문제가 있다고 가정하면 된다.
lock 도 운영체제마다 다르고 ex) window 에서는 criticalSection 등등 사용했지만
C++11 에서 부터는 mutex라는 개념을 사용.
#include<mutex>
[ mutex와 semaphore 의 차이점 참고 ]

물론 경합이 심해져서 한번에 한명만 통과할 수 있기 때문에 싱글쓰레드로 동작하는 개념이라고 생각할 수 있다.
더군다나 lock은 재귀적으로 작동이 안되게 때문에 lock 하고 또 lock안에서 또 lock이 안된다. ( 따로 recursive lock이 존재한다. )
그리고, 예외처리나 코드가 길어져서 unlock을 못하는 경우도 생기기 때문에 수동으로 lock, unlock 하면 나쁜 습관이다.
그래서 그 유명한 RAII (Resource Qcquisition is Initialization) : 자원의 획득은 초기화다.
즉, 자원관리를 스택에 할당한 객체를 통해 하는것이다. ( 스택은 반드시 소멸되기 때문에 )
예외가 발생해서 함수를 빠져나가더라도, 그 함수의 스택에 정의되어 있는 모든 객체들은 빠짐없이 소멸자가 호출된다(이를 stack unwinding 이라 한다). 물론 예외가 발생하지 않는다면, 함수가 종료될 때 당연히 소멸자들이 호출된다.
그렇다면 생각을 조금 바꿔서 만약에 이 소멸자들 안에 unlock을 하는 루틴을 넣으면 어떨까?
어떤 Wrapper 클래스를 만들어서 생성자에서 잠구고, 소멸자에서 풀어주고 하는 그런 행동들을 할 것이다.

그리고 매번 LockGuard를 직접 만들어야되는것은 아니고
std::lock_guard<T> 라고 표준에 있다. (똑같은 코드다 )
참고로
std::unique_lock<T> 는 당장 lock_guard를 만든 시점에 lock을 잠구지 않고, lock을 하는 시점을 따로 명시적으로 해줄 수 있다.
물론, lock_guard 와 마찬가지로 소멸할때 같이 소멸된다.

'C++과 언리얼로 만드는 게임 개발 > Part4. Server' 카테고리의 다른 글
| Lock 구현 이론 | V (0) | 2022.04.28 |
|---|---|
| ★(중요_다시듣기)★DeadLock | V (0) | 2022.04.28 |
| Atomic 동기화 방법(1) | V (0) | 2022.04.27 |
| 쓰레드 생성 | V (0) | 2022.04.15 |
| 환경 설정 (0) | 2022.04.12 |