멀티쓰레드는 지금까지 내가 알던 프로그래밍 세계와는 다를 것이다..
지난 수업과 다르게 이번 수업은 코드를 먼저 살펴본다.
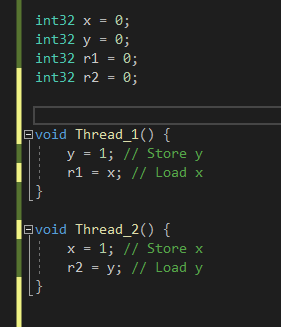
Thread_1() 이라는 함수와 Thread_2() 라는 함수를 정의했는데
주석에 담긴 의미로 동작한다고 생각해보자.
그리고 main 함수에서 쓰레드를 생성해주고 쓰레드가 각각의 함수를 실행한다고 해보자.
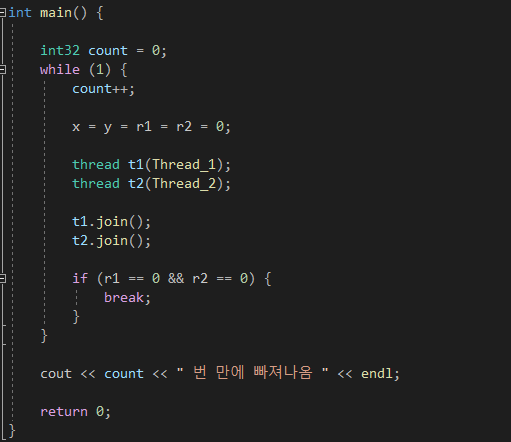
우리가 알아 보고 싶은것은
r1==0 이고 r2==0 동시에 0 일때가 있는지를 확인하고 싶고,
만약 그렇다면 while 문을 빠져나오게끔 해준다고 해보자.
그리고 빠져나왔다면 count 변수를 두어 몇 번 만에 빠져나왔는지 결과를 봐보자.
하나 더 , c++ 에서 쓰레드를 만드는 작업이 생각보다 무거운 작업이다 보니깐 비유하자면 시~작 하면 두 쓰레드가 동시에 실행되게끔 해보자.
타이밍 이슈를 조금 조절하기 위해 ready 라는 bool 변수를 두는 것이다.
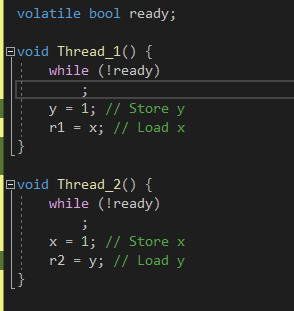
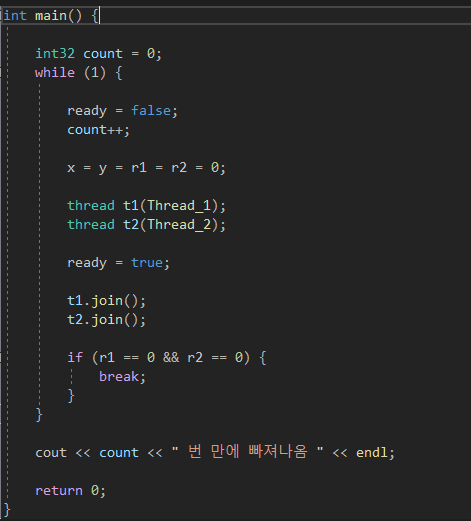
일단 쓰레드가 실행할 함수 안에서 ready가 false 일 때는 대기 하게끔 해놨다.
그리고 main 함수 안에서 처음에 ready를 false 로 두어 t1, t2 어떤 쓰레드도 Thread_1() , Thread_2() 함수안의 while문을 빠져나가지 못하게 하다가 t1,t2 가 전부 생성이 되었을때 ready 를 true로 바꿔주어 while문을 빠져나오게 해줬다.
조금이나마 동시성을 컨트롤 해줬다고 생각하면 될 것 같다.
전역변수 ready를 volatile 로 둔 이유는
컴파일러가 최적화를 한답시고 일부로 ( 생각있이 ) 만들어 놓은 코드를 바꿔 놓을까봐 넣어줬다.
다시 말해, 원래 알맞은 순서는
ready=false 를 해주고 쓰레드 t1,t2 생성후 ready= true 로 바꿔주는게 의도한 코드인데,
이를 무시하고 코드의 결과만 보고 ready를 그냥 true로 최적화하여 컴파일 하는것을 막기 위해서이다.
( a = 1; a = 2; a = 3 ; 을 컴파일 하면 그냥 a = 3; 만 넣는다는 식의 최적화를 막기 위해 )
강사님 말로는 환경에 따라 결과가 다르게 나올 수 있다고 말한다.
( 우선 강사님 컴퓨터는 빠져나왔는데 내 컴퓨터에서는 빠져나오지 못했다. )
우리는 쓰레드 t1, t2 가 각자의 함수를 수행하는데, 어떤 쓰레드던간에 둘 중에 조금이라도 먼저 실행된다면 r1 이나 r2은 절대 동시에 0이 될 수 없을것이라고 생각 할 것이다.
이거는 내가 지금까지 알던 싱글쓰레드 관점에서의 생각이다.
그럼 이게 왜 r1도 0이고 r2 도 0이 되어 빠져 나왔을까?
( 해결하는 방법은 다음 시간 메모리 모델에 대해서 알아보면서 알아보자. )
일단 문제 자체가 일어나는 이유는 두 가지 이다.
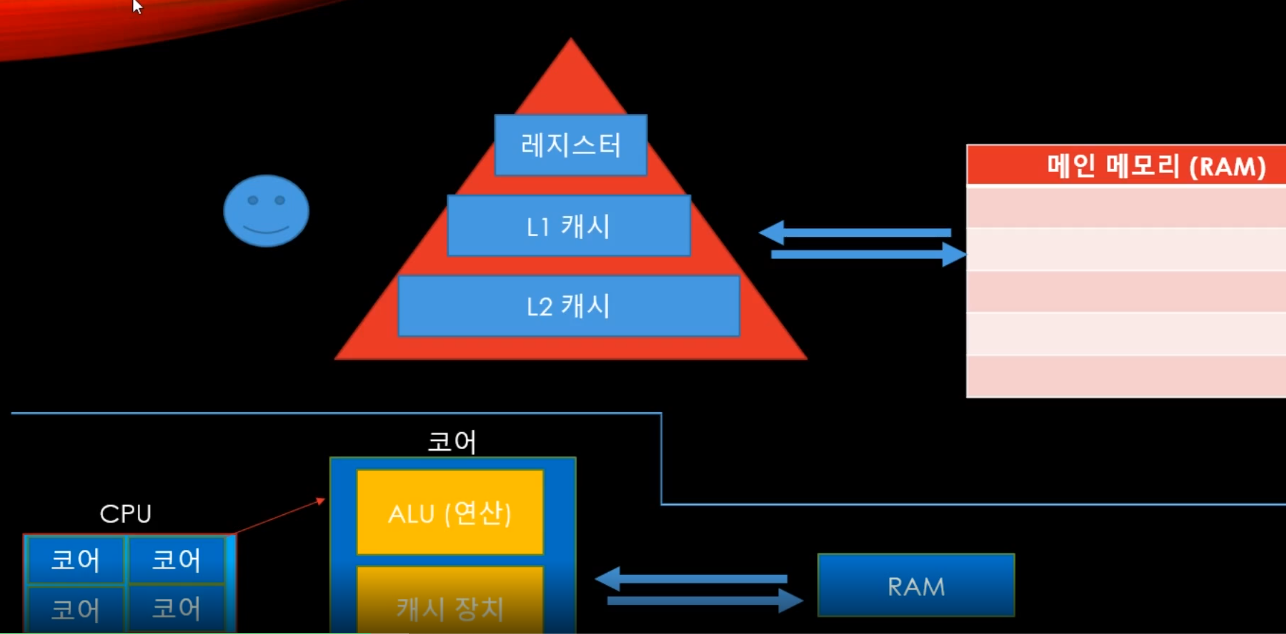
1. 가시성
- 이전에 얘기했던 캐시에 관한 이야기이다. CPU 가 어떤 값을 읽거나 쓸 때 RAM으로 곧이 곧대로 가지 않고 캐시에 값이 있다면 캐시에서 읽거나 쓸 수 있다.
그리고 중요한 점은 CPU 는 각 코어마다 자신만의 별도의 캐시를 가지고 있다.
그럼 이게 무슨 상관이냐?
만약 Thread_1() 에서 y=1을 넣는데
물론 정확한 정책은 알 수는 없지만, 이게 진짜 RAM까지 가서 데이터를 썻다는 보장이 없을 뿐더러, 동일하게 Thread_2( 에서 메모리에 있는 값을 불러왔다는 보장도 없다는것이다.
단일 쓰레드 기준에서는 아무런 상관이 없던 내용인데, 다수의 쓰레드가 개입되는 순간 머리가 어지러워지기 시작한다.
( 단일 쓰레드 기준으로 Thread_1에서 내가 y에 1을 넣으면 해당 코어의 캐쉬 메모리에 y=1이 들어갈 수도 있고, 메모리에 1이 들어가 있을 수도 있다. )
즉,
Thread_1 에서 y=1을 넣었는데 반대편(Thread_2)에서 아직은 y가 1을 읽지 못할 수도 있는것이다.
이런걸 말그대로 가시성이라고 표현한다. 기본 상태로는 가시성을 항상 보장하지 않기 때문에 문제이다.
그리고 C# 기준으로 보면은 volatile 키워드를 붙히면 컴파일러 최적화도 막아주고, 가시성도 보장해주기 때문에
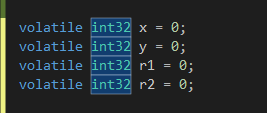
이런식으로 volatile 키워드를 붙혀주면 가시성은 해결이 된다.
( c++의 volatile 은 단순히 컴파일러의 최적화를 막는 역할만 한다. )
그리고 c#에서 volatile을 붙혀서 실행해도 문제가 발생하는데, 그렇다는건 아래 나올 2.코드 재배치도 문제도 문제라는 것이다.
2. 코드 재배치
우리는 지금 까지 CPU와 컴파일러한테 속고 있었다.
컴파일러가 기계어로 변환할때 항상 우리가 작업한 곧이 곧대로 번역해주지 않을 수 도 있다.
예를 들면, 아래의 코드를 컴파일러가 컴파일하다가
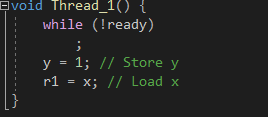
아래 처럼 순서를 바꾸는게 빠르다고 판단 되면 아래처럼 코드 순서를 뒤바꿔 줄 수도 있다는 것이다.
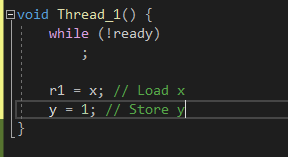
일단 컴파일러 입장에서는 멀티쓰레드를 생각안하고, 단일 쓰레드 입장에서 실직적으로 Load를 먼저 하는게 성능적으로 이득이고, Thread_1() 함수만 봤을때 로직적으로 변하지 않는다고 판단되면 합법적을 바꿔 줄 수 있다.
즉, 컴파일러 입장에서는 y=1 대입하는거랑 r1=x 를 대입하는거는 서로 별반 상관이 없기 때문에 뒤 바꿔도 상관없다고 판단하는것이다.
( 물론 항상 이런것은 아니고 단일 쓰레드에서 결과물이 똑같다는 보장이 있을때만 바꿀 수 있다. )
그리고 설령 컴파일러가 이런짓을 하지 않는다고 해도 CPU가 이 짓을 할 수도 있다.
우리가 지금까지 했던 싱글쓰레드 프로그래밍에서 이런게 아무런 문제가 없었던것은 순서를 뒤바꾸나 냅두나 아무런 상관이 없었기 때문에 우리가 몰랐던 것이다.
이제 멀티쓰레드 환경에 오니깐 우리가 예상하지 못했던 문제가 발생하기 시작하는것이다.
그러면 바보도 아니고 왜 CPU나 컴파일러는 이런짓을 할까?
무슨 특별한 이유가 있을 것이다.
[ CPU 파이프 라인 ]
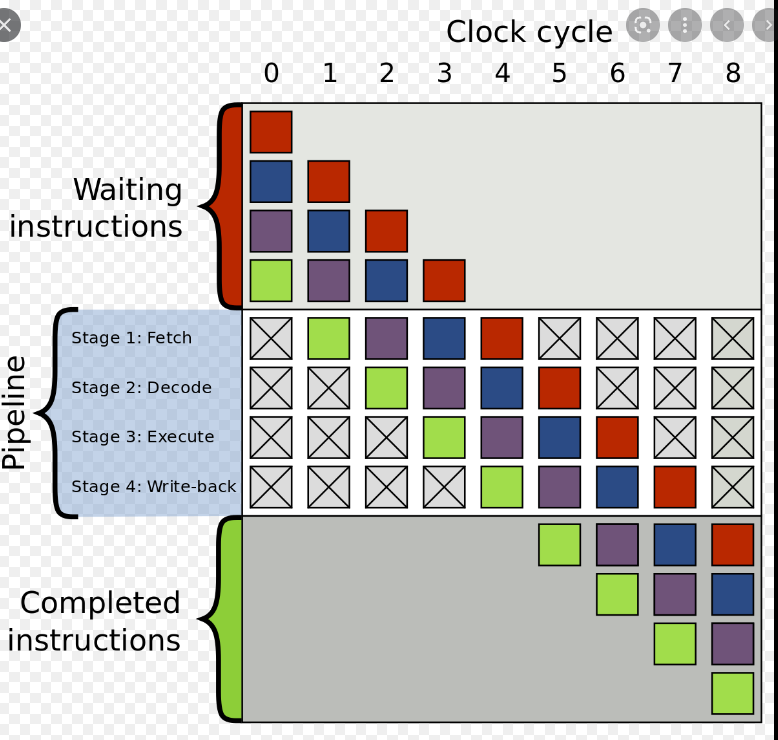
명령(instruction)에 따라서 각각의 단계마다 걸리는 시간이 다르기 때문에
CPU가 명령들을 곧이 곧대로 받은 순서대로 진행하는것 보다 테트리스 하듯이 중간에 순서를 효율적으로 배치하는게 모든 명령어를 실행하는데 효율적이기 때문이다.
CPU 입장에서는 모든 명령어를 다 수행해야되는 입장이지 명령어들 사이의 순서가 없다고 한다면 주문 받은 순서대로 해야 하는 강압적인 이유는 없다.
성능 향상을 위해 컴파일러 혹은 CPU가 알게 되면
알게 모르게 이런것을 해주고 있었다.
단일 쓰레드에서는 우리가 인지하지 못했던것이다.
해결책 : 메모리 모델
C++11 이전에는 모든 모델이 싱글쓰레드 기준으로 생각했다.
C++11 이후에는 멀티쓰레드를 잘 고려해주기 때문에 라이브러리 차원에서 지원을 해주게 됐다.
그래서 C++에서 제공해주는 그런 방법을 토대로 코드를 만들면 어떤 머신이건 프로세스이건 상관없이 표준에 의해서 이런 상황을 미연에 방지할 수 있다.
지금까지 우리는 atomic 클래스를 기본 값 클래스로 사용하고 있었다.
세부적인 설정을 통해서 메모리를 어떻게 관리할지, instruction을 뒤바꿔도 되는지, 가시성은 어떻게 할지 해줄 수 있다.
'C++과 언리얼로 만드는 게임 개발 > Part4. Server' 카테고리의 다른 글
| Thread Local Storage ( TLS ) | V (0) | 2022.06.14 |
|---|---|
| ★진짜 진짜 중요!!!★메모리 모델 | atomic 클래스/ 가시성 / 코드 재배치 (0) | 2022.06.08 |
| std::future | V (0) | 2022.05.21 |
| Event ( 커널 오브젝트, CreateEvent, WaitForSingleObject ) | V (0) | 2022.05.02 |
| ★엄청 중요★ Spin Lock ( feat. volatile, compare_exchange_strong() ) | V (0) | 2022.04.29 |