C+11 에서 추가된 가장 중요한것은?
Memory Model
[ 복습 ]
여러 쓰레드가 동일한 메모리에 동시에 접근할때, 특히 누구 하나가 Write 연산을 할 때
Race Condition 이 일어난다.
이를 Undefined Behavoir 이라고 한다.
우리가 배운 해결책 :
- > 1. Lock (mutex ) 를 이용한 상호 베타적 (mutual exclusive 하게 ) 접근
- > 2. Atomic ( 원자적 ) 연산을 이용.
오늘은 2. Atomic 원자적 연산을 심화해서 알아보자. ( 사실 원자적 연산이 바로 문제를 해결해주지는 않는다. )
유일하게 C++ 에서 고증하는 하나의 절대 법칙이 있는데 아래의 내용이다.
atomic 연산에 한해, 모든 쓰레드가 동일 객체 대해서 동일한 수정 순서를 관찰한다.
*여기서 말하는 원자적 연산은 꼭 atomic 클래스 만을 말하는것은 아니다. 말 그대로 모든 원자적 연산을 의미한다. 후에 예시로 살펴보자.
그럼 위의 인용된 글이 무슨 의미인지 알아보자.

우리는 위와 같은 코드를 보면 atomic 한 객체 num을 수정하는거기 때문에, 두 쓰레드가 동시에 실행 된다고 하더라도 예측하지 못한 행동이 아니라 반드시 어떠한 쓰레드가 조금이라도 먼저 실행 된다면, 1 이나 2 둘 중에 하나로 바뀔 것을 확신 할 수 있다.
간발의 차로 Thread_1() 이 실행 되면은 num은 1이 될거고 반대는 2가 될 것이다.
여기서 아래와 같은 함수로 num 의 값을 관찰하는 쓰레드가 있다고 해보자.

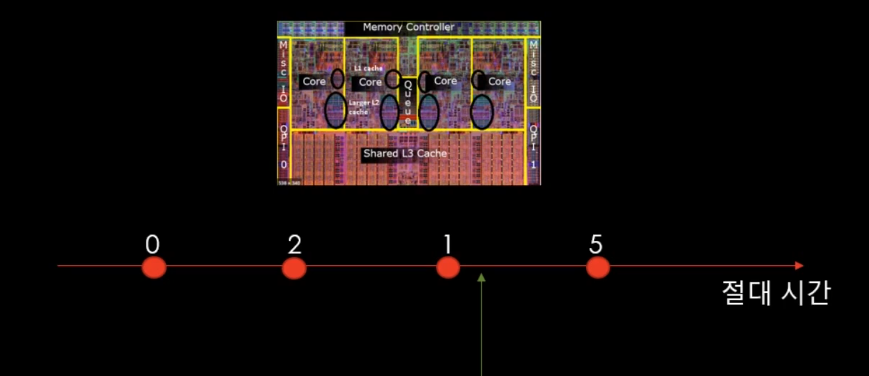
코어마다 캐쉬가 있기 때문에 다른 쓰레드에서 관찰했을때 num 이라는 값이 실제로 1이나 2로 바뀌었다고 확인 할 수 있을지 확신 할 수 없다. ( 지난 시간에 배운 가시성 문제 )
그리고 num 의 값이 쓰레드들에 의해 0 2 1 5 순서로 변한다고 해보자.
우선 동일한 수정 순서를 관찰 한다는 말은
관찰하는 쓰레드가 2를 관찰 했다가 절대 시간이 흐른 다음에 다시 한번 관찰 했을때 2,1,5 로 관찰 할 수 있지, 그 이 전 값인 0을 관찰 할 수는 없다는 소리이다.
그리고 여기서 한 가지 중요한 점은 0 2 1 ^ 5 : ^ 부분에서 관찰 쓰레드가 관찰 했을때 1를 관찰 해야 될 것 같은데 꼭 1를 관찰한다는 보장은 없다는 점이다.
지난 시간에 배운 캐시나 여러가지 문제가 얽혀 있기 때문에 당장 1이라는 숫자를 보지 못하고 예전에 있던 2라는 값을 관찰 할 수 있다는 것이다.(가시성 문제 )
동일한 수정 순서라는게 반드시 0 2 1 5 의 순서로 시간의 흐름이 진행이 된다는 것이고, 반대로 얘기하면 내가 지금 2라는 수를 관찰했는데 다시 관찰 했더니 0 으로 관찰 할 수는 없다는 소리이다. ( 동일한 수정 순서를 관찰 한다는 소리 )
그리고 반드시 0 2 1 5 순서는 아니고, 1은 스킵하고 0 2 5 순서로 관찰 결과가 나올 수도 있다.
*여기서 말하는 원자적 연산은 꼭 atomic 클래스 만을 말하는것은 아니다. 말 그대로 모든 원자적 연산을 의미한다. 후에 예시로 살펴보자.
좀 전에 미룬 예시를 찾아보자.
CPU 가 한번에 처리 할 수 있는것을 원자적 연산이라고 하는데
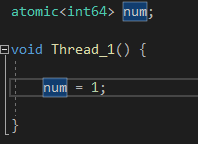
CPU 자체가 64bit 이기 때문에 어지간하면 int64 객체 num 에 1을 대입하는 것은 원자적인 연산으로 해결 할 수 있을 것이다.
만약 예전 32bit 체재였으면 내부적으로 int64를 한번에 처리 할 수 없기 때문에 int32 두개를 만들어서 상위비트/하위비트로 나눠서 2번에 걸쳐 연산을 해서 1을 대입했을 것이다. ( 이런것은 원자적 연산이라고 말 할 수 없다. )
- 결론 : 원자적 연산은 CPU에 상대적이다. (어떤 환경에서는 원자적이고, 어떤 환경에서는 원자적이 아니다. )
만약 원자적으로 잘 실행되는지 궁금하면은
atomic 클래스의 is_lock_free() 함수를 통해 체크 할 수 있다.
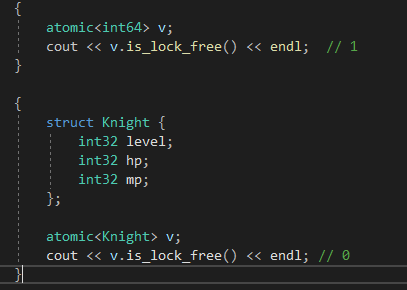
만약 true 가 나온다면 본인의 컴퓨터에서 원래 원자적으로 수정할 수 있도록 지원해준다는 소리이고,
false 가 나온다면 CPU 차원에서 해당 객체를 원자적으로 수정 할 수 없기 때문에 어거지로 , lock을 잡아서 이게 원자적으로 수정되게끔 유도해준것이다.
동일 객체 에 대해서 동일한 수정 순서를 관찰한다고 했는데 여기서 또한 중요한 말은 동일 객체 라는 말이다.
atomic<int64> num 이라는 동일 객체에 대해서는 동일한 수정 순서를 보장하지만,
num2 , num3 등등 이 있어서 같이 수정한다고 한다면 동일한 수정 순서를 보장하지는 않고 개내들끼리 엎치락 뒤치락 할 수 있는 것이다.
결론 : 지난 시간에 문제가 됐던 가시성, 코드 재배치 문제는 atomic 연산을 한다고 해가지고 해결되지 않는다.
1. num1 을 먼저 수정하고 num2 수정했는데 순서가 뒤바뀐다는게 코드 재배치 문제와도 유사하고,
2. 수정 순서를 관찰한다고 해도 가시성 문제는 해결되지 않는다. num이 2로 바뀐 다음에 num을 관찰 했을때 가시성 문제가 해결이 될라면 무조건 2가 관찰 되어야 되지만, atomic은 사실 이제까지 관찰한 어떤 값을 기준으로 그 이후 어딘가를 관찰한다는 것 뿐이다. ( 2가 아닐 수 도 있다. )
그럼 코드를 통해 여러가지 실습을 해보자.
실습에 앞서 아래의 코드들은 동일한 말이다. ( 메모리 정책 옵션 )


defalut로 memory_order :: memory_order_seq_cst 라는 메모리 정책을 사용하고 있었다.
메모리 정책이 하나만 있는게 아니다.
어떤 메모리 정책에 따라서 우리가 문제시 했던 가시성이나 코드 재배치 문제가 해결되고 아닐 수도 있다.
[ 실습 ]

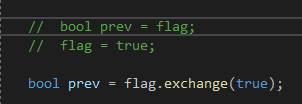
만약 flag 값을 꺼내서 저장한 다음에 flag값이 false 일때만 어떤 행동을 하고 flag를 true로 수정한다고 한다면 보통은 아래와 같이 할 것이다.

근데 이 코드는 문제가 있다. ( atomic 과 관련된 코드를 작업할때 주의해야할 부분 )
첫번째, 우리는 flag의 이전 값(false)를 가져와서 prev 에 넣었다고 생각 할 수도 있겠지만
그 순간에 다른 쓰레드가 flag에 접근해서 true로 바꿨다면 더 이상 flag 값은 유효하지 않게 된다.
두번째, 어찌 해서 flag 값이 prev 에 잘 들어갔다고 해도 그 다음 flag 값을 if문으로 체크할때 바로 직전에 flag 값이 다른 쓰레드에 의해 true로 변경된다면 우리는 prev 값이 false 니깐 당연히 if문에 걸려서 Do Something을 할 것이라고 생각하지만 실상은 if문에 걸리지 않게 된다.
그래서 결론은 flag 값을 꺼내서 수정하는것도 원자적으로 동시에 되야된다.
혹은


만약 flag 값이 expected가 아니면 (true 라면) expected = flag ; 로 변경 되고 return false 를 해준다.
의사코드로 표현하자면

이것을 이용해서 spin lock도 만들수 있었고, 마지막 인자로 memory_order로 여러가지 메모리 정책을 변경할 수도 있다.
참고로 compare_exchange_weak도 있는데 사용방법은 거의 똑같은데, 한 가지 차이점은
spurious failure (가짜 실패?) 라고해서
내부적으로 만약에 flag 랑 expected가 같으면 flag가 desired 로 바뀌면서 return true를 해주는데
// TODo
compare_exchange_strong 과 compare_exchange_weak 의 차이점.
우선 동작 방식은 비슷한데 내부적으로 조금 다르다.
weak는

기본형은 compare_exchange_weak.
strong 은 이러한 상황을 없앴다기 보다는 이런상황이 일어났을때 우리가 원하는 올바른 결과가 나올때까지 반복을 해준다고 보면 된다. 결과를 보장해줘야 되기 때문에 weak 보다 strong 버전이 부하가 조금 더 있다.
그래서 compare_exchange_weak 는 무조건!!! while 문이랑 같이 사용을 해서 될 때까지 뺑뺑이를 돌리는게 정석이다.

근데 사실 intel 머신에는 strong이나 weak나 성능 차이가 크지 않다.
참고 : http://egloos.zum.com/sweeper/v/3059861
[C++11] atomic
1. std::atomic atomic 클래스는 정수형 또는 포인터 타입에 대해 산술 연산들을 atomic하게 수행할 수 있도록 해 주는 템플릿 클래스이다. (더하고 빼고, 그리고 and/or/xor 등의 비트 연산들...) 이전에는 a
egloos.zum.com
그리고 그냥 exchange 함수도 있는데 compare 하지 않고 이전 값 리턴과 수정을 원자적으로 수행한다.

[ 메모리 정책 ]
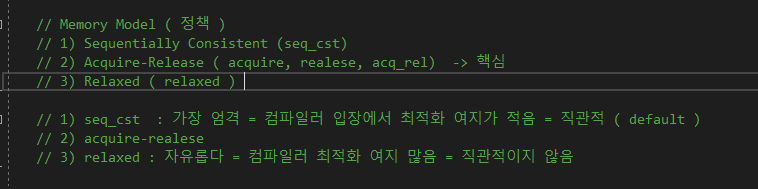

아무것도 입력하지 않는 다면 atomic 클래스는 seq_cst 메모리 정책을 default로 가지고 있기 때문에 코드 재배치와 같은 문제도 잘 안 생길 것이고, 아래로 내려갈 수록 최적화 여지가 많기 때문에 지들끼리 섞고 난리도 아닐것이다.
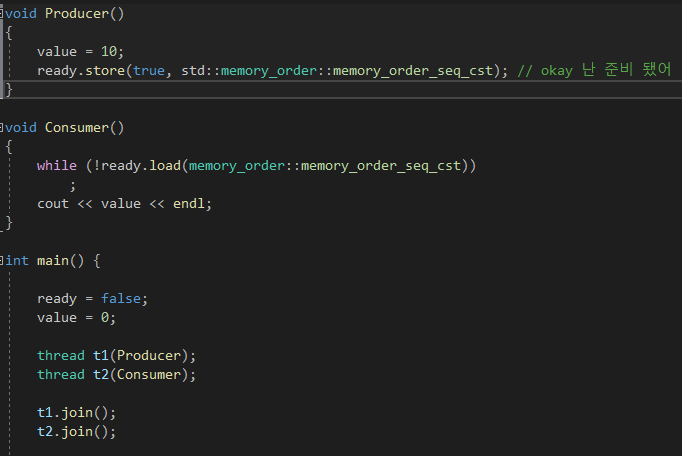
1) seq_cst 를 사용하면 지금까지 문제가 됐던 가시성 문제랑 , 코드 재배치 문제가 바로 해결이 된다.
- Producer 에서 ready에 true를 넣으면 그걸 사용하게 되는 어떤 쓰레드나 true 값을 보게 된다.
(원래는 CPU는 캐시나 여러가지 복잡한것들이 얽혀 있어 CPU 들끼리 서로 보고있는 메모리가 다를 수 있는데 이 때 가시성 문제가 생긴다. )
3) relaxed : 코드 재배치도 멋대로 가능! 가시성 해결 NO!
가장 기본적인 조건인 : 동일 객체에 대한 동일 관전 순서만 보장
그래서 relaxed 같은 경우에는 진짜 거의거의 사용할 일이 없다. ( 멀티 쓰레드 환경에서 거의 재앙 수준이다. )
2) acquire-release : 딱 중간 수준
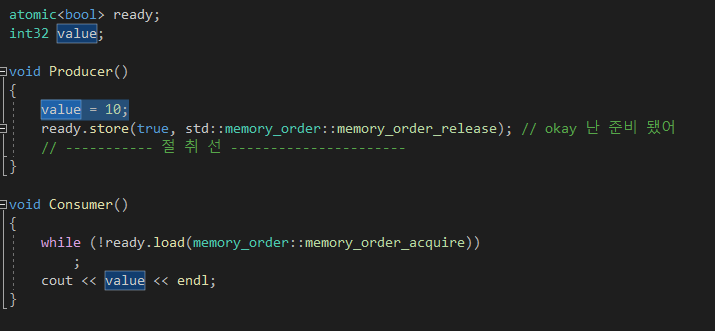
- release 명령 이전의 메모리 명령들이 , release 명령 이후로 재배치 되는 것을 금지
그러나 relase 위에 여러가지 값들이 있었다면 그 위에서 코드 재배치가 되는것은 막지 못한다.

그리고 acquire 로 같은 변수를 읽는 쓰레드가 있다면
release 이전의 명령들이 -> acquire 하는 순간에 관찰 가능하다. 즉 가시성이 보장된다.

마찬가지로 절취선을 그어가지고 acquire 아래 있는 명령들이 위로 올라가는것을 막을 뿐만 아니라
store 랑 짝짝궁 맞아가지고 release 이전의 값들이 acquire 이후에 모두 갱신이 되서 정확히 가시성이 보장이 된다.
한 가지 기쁜 소식은 인텔이나 AMD의 경우 애당초 순차적 일관성을 보장을 해서
seq_cst 를 써도 별다른 부하가 없다. 그래서 그냥 memory_order 를 신경쓰지 않고 default로 하는게 가장 맘 편하다.
ARM은 좀 다르다고 한다.
결국에는 우리가 캐시나 파이프라인 , 메모리 정책에 대해서 알아봤는데 이걸 사실 아나 모르나 기본 상태로만 사용했어도 별 문제 없이 돌아간다는 것을 알 수 있다.
조금 허무할 수도 있는데 이런 부분들에 대해서 알긴 알아야 하니깐 한거다.
________
atomic_thread_fence(require) 같은 기능도 있는데 그냥 일반 atomic 쓰면은 포함되는거긴 해서 굳이 안써도 되는데 기능이 있다는건 알아두면 좋고
자세한 내용은 강의 후반부 참고하자.
'C++과 언리얼로 만드는 게임 개발 > Part4. Server' 카테고리의 다른 글
| ★(중요)Local-Based Stack/Queue | V (0) | 2022.06.25 |
|---|---|
| Thread Local Storage ( TLS ) | V (0) | 2022.06.14 |
| 캐시 & CPU 파이프라인 ★★ 문제 제시 | V (0) | 2022.06.06 |
| std::future | V (0) | 2022.05.21 |
| Event ( 커널 오브젝트, CreateEvent, WaitForSingleObject ) | V (0) | 2022.05.02 |